I Haven't Hand-Written a PR in Months
With 30 minutes left in my day, I drop a stack of well-defined Linear tickets into Todo, set Amphetamine to keep my laptop awake, and close the lid.
By morning, the PRs are open, CI is green, and code review comments are addressed.
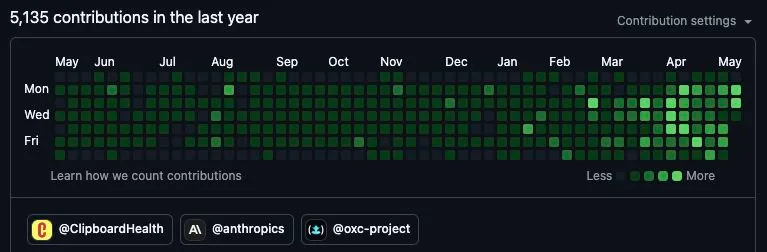
I haven’t hand-written a PR in months. Clipboard has tripled deploys per engineer.
This is not because the agents became magical. The workflow works because the tickets are clear, the loops are tight, and the guardrails are explicit. Any ticket I can specify clearly can usually move through plan, ship, review, and fix without me sitting in the middle.
The system opens 50+ PRs a day and burns 9.5B tokens a month. At retail API rates, that would be over $7,000, but Claude Code Team and Codex Pro plans cover it. The stack has a few parts, three of which we just open-sourced.
The Stack
Two Agents, Not One
Codex is the better debugger and reviewer. Claude Code is the better designer.
That split matters. I do not want one general-purpose agent doing every job equally well. I want the right agent on the right class of work, and I want another model available when the first one gets stuck or starts arguing with reality.
Two plans also mostly keep me under rate limits. That sounds like an implementation detail until you are trying to run agent work overnight and need enough headroom left in the morning to keep working.
cmux for Parallel Sessions
cmux is the terminal layer. It is Ghostty-based, supports native notifications, and gives each agent an actual terminal session.
That last point is important. I want to run the real Claude Code and Codex CLIs, not a wrapper that approximates them. Zed Parallel Agents and tools like Conductor are useful, but this workflow depends on the exact local tools I already use during the day.
groundcrew for Farming Tickets to Agents
groundcrew watches a Linear board and farms tickets to local agents.
Local agents are more steerable than remote agents. They run in my environment, use my local tools, and can be nudged when they drift. groundcrew tracks 5-hour and weekly usage limits so overnight lint cleanup does not burn the headroom I need the next morning.
The agents run in cmux workspaces, backed by git worktrees inside agent-safehouse sandboxes, which makes more aggressive agent modes safer to use. Shout out to Clayton Winders for the initial version.
clearance for Network and Host Isolation
clearance combines agent-safehouse host-OS isolation with a deny-by-default HTTP proxy.
The goal is simple: if a runaway agent tries to exfiltrate data, the host and network boundaries should stop it. groundcrew uses clearance transparently, so the safety layer is part of the normal workflow instead of a separate ritual I have to remember.
babysit-pr for the Last Mile
/babysit-pr watches each PR after it opens. It fixes CI failures, handles merge conflicts, and triages review comments into three buckets.
- If it agrees, it pushes the fix and replies with a commit link and a one-line summary.
- If it agrees but the request would bloat the current PR, it opens a follow-up PR.
- If it disagrees, it replies with the reason.
That is the difference between “an agent opened a PR” and “the PR kept moving after the first human or CI system pushed back.”
What Changed
The biggest change is not that I type less code. It is that the feedback loop now runs without me as the bottleneck.
Before, I was in the middle of every step: plan, ship, review, fix. Now I spend more time deciding what to build, writing the rules and feedback loops that keep agents honest, and proving the result.
This only works for tickets that can be specified clearly. Vague work still needs human shaping. Ambiguous product decisions still need judgment. But once the work is crisp enough to hand to another engineer, it is often crisp enough to hand to an agent.
That changes the job. I still review, but I review the system as much as the diff. I ask whether the ticket was scoped correctly, whether the guardrails caught the right failures, whether the agent had enough context, and whether the workflow produced evidence I trust.
The output is not just more PRs. The output is a tighter plan -> ship -> review -> fix loop, with humans spending more time on leverage and less time on mechanical follow-through.